|
|
| 09-17-15, 09:21 PM | #1 | |
|
A Scalebane Royal Guard

Join Date: Mar 2015
Posts: 431
|
Pattern matching optimization
__________________
Last edited by MunkDev : 09-17-15 at 09:27 PM. |
|

|
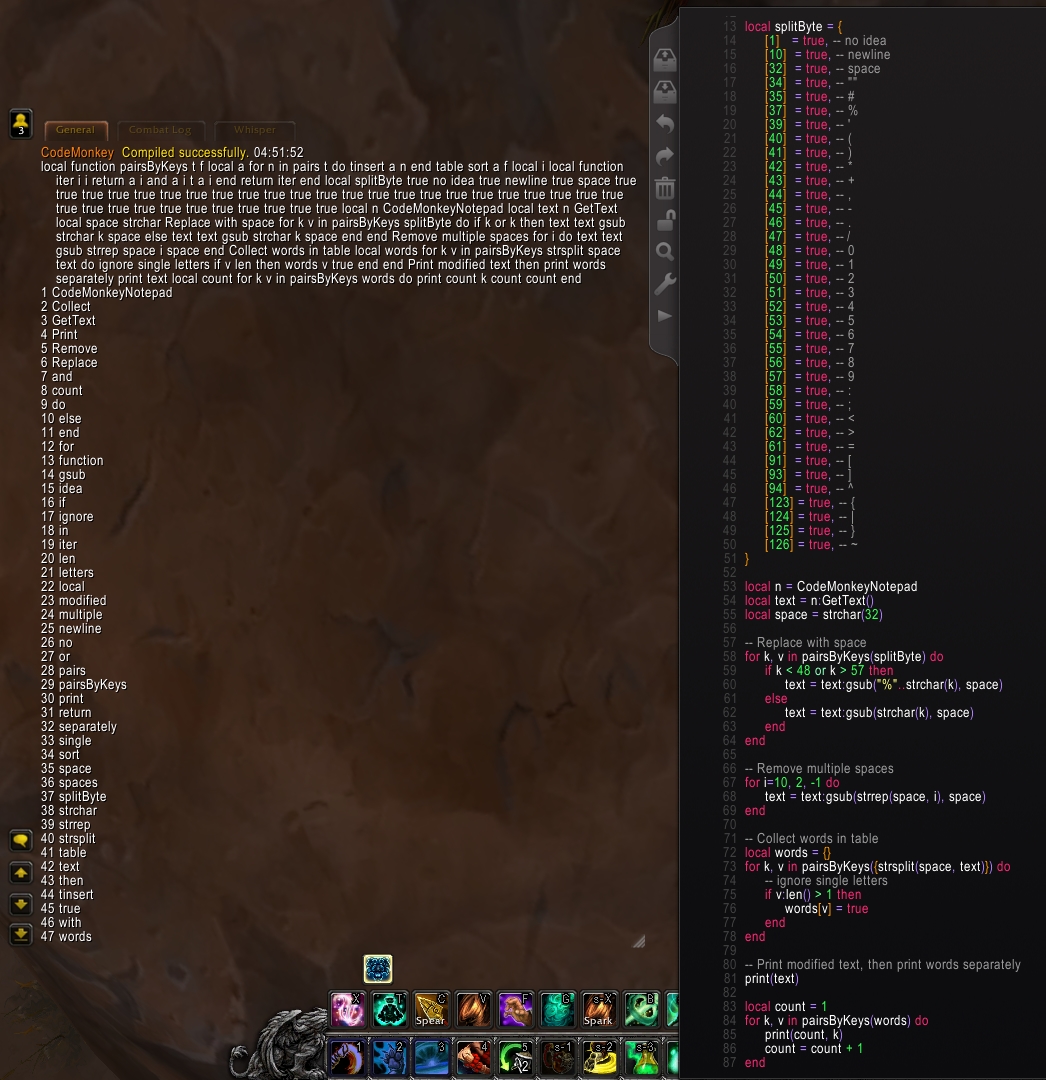
| 09-18-15, 07:13 AM | #2 | |
|
A Molten Giant

Join Date: Nov 2006
Posts: 554
|
__________________
Grab your sword and fight the Horde! |
|
|
|
| 09-18-15, 07:56 AM | #3 | |
|
A Scalebane Royal Guard
Join Date: Mar 2015
Posts: 431
|
__________________
|
|
|
|

| 09-18-15, 08:00 AM | #4 | |
|
Cat.

Join Date: Mar 2006
Posts: 5,617
|
__________________
Retired author of too many addons. Message me if you're interested in taking over one of my addons. Dont message me about addon bugs or programming questions. |
|
|
|
| 09-18-15, 08:14 AM | #5 | |
|
A Scalebane Royal Guard
Join Date: Mar 2015
Posts: 431
|
__________________
|
|
|
|
| 09-18-15, 08:19 AM | #6 | |
|
Cat.
Join Date: Mar 2006
Posts: 5,617
|
__________________
Retired author of too many addons. Message me if you're interested in taking over one of my addons. Dont message me about addon bugs or programming questions. |
|
|
|

| 09-18-15, 08:25 AM | #7 | |
|
A Scalebane Royal Guard
Join Date: Mar 2015
Posts: 431
|
__________________
Last edited by MunkDev : 09-18-15 at 08:51 AM. |
|
|
|

 Hybrid Mode
Hybrid Mode
WoWInterface
AddOn Sites
© 2004 - 2022 MMOUI
vBulletin © 2024, Jelsoft Enterprises Ltd